
Fit Check AI is a men's outfit AI generator tool. The project uses a fine-tuned version of the open source Stable Diffusion XL base model and has been trained on hundreds of curated menswear outfits. The training data consisted of outfit pics from various men's style influencers, eaching showcasing modern style trends and fits.
Users enter a prompt that directs the AI towards a particular style or outfit type. Additional prompting text is then added to the user's input in the background to ultimately achieve the desired fashion photography look.
I used the online AI training platform Replicate to fine-tune the base Stable Diffusion XL model with ~300 outfit images. These images consisted of curated outfit pics from Instagram fashion influencers I follow. The images were not quite high quality (~1800 x 1440) as they were being scraped from Instagram. Thankfully, Replicate upscales the images as part of its preprocessing.
Before training starts, Replicate preprocesses the input images using multiple models:
I experimented with various amounts of training steps (1K, 4K, 10K, 15K) and ultimately received the best results at 4K training steps. Higher amounts of training steps led to overfitting where the model would simply return existing outfits from the training images. 4K steps was just enough to train the model on the general style while not overfitting.
The learning rate controls how much the model’s weights are updated in response to the prediction errors. A higher learning rate means larger updates to the weights, while a lower learning rate means smaller updates. If the learning rate is set too high, the model may update the weights too drastically, leading to overshooting the optimal values. This model was trained using a U-Net learning rate of 1e-6.
The LoRA scale is the scaling factor that determines how much importance you want to give to the newly trained images as opposed to the base model. For example, a LoRA scale of 0.7 means that 70% of the combined result will come from the newly trained LoRA model while the remaining 30% will come from the base model. This helps control how much of the generated image you want to pull from the new images vs. existing training on the base model. I found the best results using a 0.7 LoRA scaling factor.
With SDXL you can use a separate refiner model to add finer detail to your output. I used the Ensemble of Experts refiner. In this mode, the SDXL base model handles the steps at the beginning (high noise), before handing over to the refining model for the final steps (low noise). This handover point, also known as the high noise fraction, had the best results at 0.9, which means that the refining model handles 10% of the training steps. I experimented with various levels of noise from 0.5 to 0.9. Using a refiner on 10% of the training steps helped add detail to the generated face and body. Higher levels of refinement led to too much detail and a fake look.
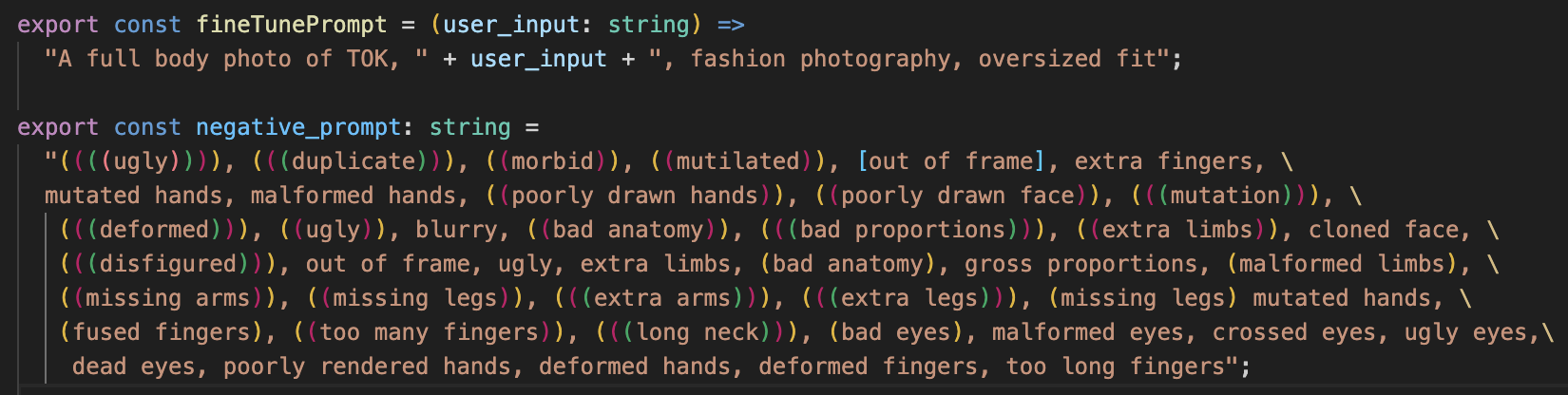
Prior to sending the prompt to Replicate for image generation, the user's input is edited to include some additional prompting language to achieve the desired style. This includes key terms such as "fashion photograph", "full body", and "oversized fit". The keyword "TOK" represents a unique string that is used to refer to the concept in the input training images. It directs the model towards the outfit images I provided.
The negative prompt helps signal what you don't want to see in the generated images. When specified, it guides the generation process not to include things in the image according to the given text. Prompting generally requires a lot of trial and error to see what works.
Given the time required to manually caption 300+ images, I relied on automated image captioning to generate captions for each image prior to training. This worked fairly well for the most part, but was not fully accurate. Common misslabeling included detecting multiple people when the image only had one person, detecting a woman when the images were only of men, and occasional wildcards like "pregnant man with a white hoodie and black pants". Manual, human-based captioning would likely produce better results but would require time investment.
The training images consisted of outfits on multiple different men with deferring heights and body proportions. When creating the generated image, the model merged all these men together, creating some irregularities to the body. This issue can be prevented by using training images from a single fashion influencer. However, this would limit the model's creativity as a single influencer usually has a distinct style.
To overcome this issue, I used a refiner model (see section above) to add facial detail and normalize any body irregularites. Once my fine-tuned LoRA model had processed 90% of the training steps, this refiner model would process the remaining 10%, helping normalize any body irregularities introduced from my LoRA model.
Based on Replicate's experimentation, LoRA seems to do a better job at detecting styles than DreamBooth, but faces aren’t as good. They are stuck in an uncanny valley, rather than looking precisely like the person. I ran into this issue as well, partly due to the challenge of using multiple influencers. The refiner model and the negative prompts helped produce more aesthetic facial features, although you can still see some irregularities in the output image.